Golang Goroutines and Channels with Custom Types
In the previous post, we had a look at how to wait for goroutines to be finished before moving on. In this post, we'll have a look at using custom types with them. If you want to have a look at the Go Goroutine and channel basics, have a look at Goroutines, Channels and awaiting Asynchronously Operations in Go.
When using Goroutines and channels, chances are you want something to happen that is very specific to your program and not necesserily just a collection of numbers or strings.
I often use web crawling as an example, mostly because it's part of a project I'm working on. I crawl websites and either extract information or build some kind of error check or to ensure some output is as expected.
Using GoQuery to Crawl Multiple Pages Concurrently
The little program below will do the following:
- visit a page
- get the content of the
<title>tag - get the content of the meta description
- print all pages information at once
All these actions will be performed for each of the elements in the urls array, the code below is the simple version and does the crawling one page at a time:
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
)
type PageMeta struct {
Title string `json:"title"`
MetaDescription string `json:"metaDescription"`
RequestURL string `json:"requestURL"`
}
func main() {
var results []PageMeta
urls := []string{
"https://jonathanmh.com",
"https://gegenwind.dk",
"http://photographerexcuses.com",
}
for _, element := range urls {
result := getMeta(element)
results = append(results, result)
}
fmt.Println(results)
}
func getMeta(URLString string) PageMeta {
fmt.Printf("STARTING %v\n", URLString)
doc, _ := goquery.NewDocument(URLString)
var myMeta = PageMeta{}
myMeta.RequestURL = doc.Url.String()
myMeta.Title = doc.Find("title").Contents().Text()
doc.Find("meta").Each(func(index int, item *goquery.Selection) {
if item.AttrOr("name", "") == "description" {
myMeta.MetaDescription = item.AttrOr("content", "")
}
})
fmt.Printf("RETURNING %v\n", URLString)
return myMeta
}
The output of the above code is:
STARTING https://jonathanmh.com
RETURNING https://jonathanmh.com
STARTING https://gegenwind.dk
RETURNING https://gegenwind.dk
STARTING http://photographerexcuses.com
RETURNING http://photographerexcuses.com
[{Hi, I'm JonathanMH Hi, I'm JonathanMH https://jonathanmh.com} {GegenWind We're GegenWind, a young photography (home) studio in Copenhagen. Say hello to us! https://gegenwind.dk} {Photographer Excuses https://photographerexcuses.com/}]
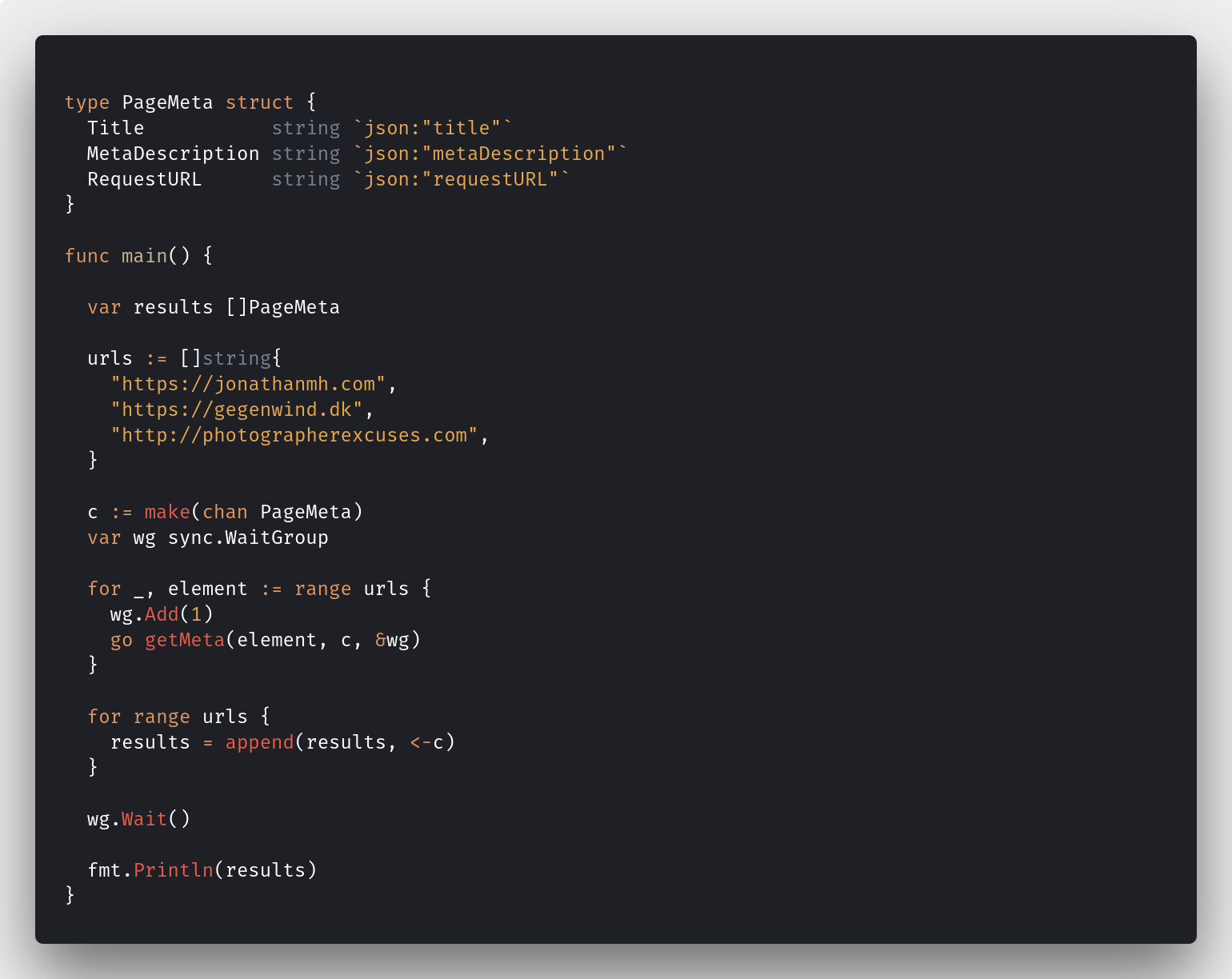
Adding Concurrent Crawling to goQuery
Network requests are much slower and there is a lot of waiting time. Any even not very powerful computer, can do many network connections at the same time. The same goes for parsing HTML and getting the content of the <title> field.
Let's make sure that we start loading each of the pages before any of them need to be finished:
package main
import (
"fmt"
"sync"
"github.com/PuerkitoBio/goquery"
)
type PageMeta struct {
Title string `json:"title"`
MetaDescription string `json:"metaDescription"`
RequestURL string `json:"requestURL"`
}
func main() {
var results []PageMeta
urls := []string{
"https://jonathanmh.com",
"https://gegenwind.dk",
"http://photographerexcuses.com",
}
c := make(chan PageMeta)
var wg sync.WaitGroup
for _, element := range urls {
wg.Add(1)
go getMeta(element, c, &wg)
}
for range urls {
results = append(results, <-c)
}
wg.Wait()
fmt.Println(results)
}
func getMeta(URLString string, c chan PageMeta, wg *sync.WaitGroup) {
fmt.Printf("STARTING %v\n", URLString)
defer wg.Done()
doc, _ := goquery.NewDocument(URLString)
var myMeta = PageMeta{}
myMeta.RequestURL = doc.Url.String()
myMeta.Title = doc.Find("title").Contents().Text()
doc.Find("meta").Each(func(index int, item *goquery.Selection) {
if item.AttrOr("name", "") == "description" {
myMeta.MetaDescription = item.AttrOr("content", "")
}
})
fmt.Printf("RETURNING %v\n", URLString)
c <- myMeta
return
}
Note that we change a couple of things to ensure that the code runs in our new and preferred order (all goroutines at once):
- we define a channel
c := make(chan PageMeta)that will transport data of the typePageMeta - we create a WaitGroup
var wg sync.WaitGroup - each time the first loop runs we add to the WaitGroup
wg.Add(1) - we pass channel and WaitGroup to the function that does the network request:
go getMeta(element, c, &wg) - we remove the return from the
getMetafunction and instead send it to the channelc <- myMeta
The output should now be as the following:
STARTING http://photographerexcuses.com
STARTING https://jonathanmh.com
STARTING https://gegenwind.dk
RETURNING http://photographerexcuses.com
RETURNING https://gegenwind.dk
RETURNING https://jonathanmh.com
[{Photographer Excuses https://photographerexcuses.com/} {GegenWind We're GegenWind, a young photography (home) studio in Copenhagen. Say hello to us! https://gegenwind.dk} {Hi, I'm JonathanMH Hi, I'm JonathanMH https://jonathanmh.com}]
Summary
If you're doing some things in series, that are not dependent on each other and that could be done in parallel, you probably should in order to speed up your program.If you're looking for a more batteries included alternative to goQuery for web scraping, you should give colly a shot, which comes with concurrency easily implementable through a config option.