Mirroring Next.js Blog to Gemini
Gemini is a smaller than HTTP protocol which only supports a smaller than Markdown syntax and supports virtually no media but ASCII art.
I like the concept and even though it's very niche, I wondered:
How hard can it be? I have all my content as .md(x) files now anyways, surely it's going to be a quick one!
I was slightly unprepared for some of the pitfalls that of course partly are a result of me using dokku for deploying a lot of my web projects. Dokku by default only lets you handle http and https connections, but there's a cool plugin that lets you handle gemini:// or other generic TCP connections.
Preparing Content for Extraction ⚒️
I'm running [Next.js][nextjs] for my main blog for a few weeks now and I really like it. I can write markdown, push to a git remote and have an article published in a workflow that fits me well. On top of that I can write JavaScript components that let me do interactive stuff like breaking down texts with virtual textmarkers or blurhash playgrounds.
The metadata for blog posts is saved in frontmatter on top of the file, easy to extract from small scripts, which I made use of for the gemlog mirror.
First I created a new directory, let's say my blog lives in jonathanmh.com and my gmi mirror at gmi-jonathanmh.com. My content is not actually served based on file path of the .mdx file, because I wanted to sort my posts into years like 2021, 2022 and so on, so I have a slug field in my frontmatter that tells Next.js the path.
This is my hacked together content extraction script, cut down a little bit for cases that might not be super relevant for you:
const fs = require('fs');
const path = require('path');
const glob = require('glob');
const matter = require('gray-matter');
const DateTime = require("luxon").DateTime;
const contentPath = path.resolve(__dirname, '../', '../', 'jonathanmh.com', 'posts');
const files = glob.sync(`${contentPath}/**/*.mdx`, {
realpath: true
});
let posts = files.map(postFileName => {
const markdownWithMeta = fs.readFileSync(postFileName, 'utf-8');
const { data: frontMatter, content } = matter(markdownWithMeta);
return {
frontMatter,
content,
isDraft: frontMatter.isDraft,
slug: frontMatter.slug,
baseName: path.basename(postFileName, '.mdx')
}
});
posts = posts.sort(function (postA, postB) {
const postADate = DateTime.fromSQL(postA.frontMatter.date);
const postBDate = DateTime.fromSQL(postB.frontMatter.date);
return postBDate.toMillis() - postADate.toMillis();
});
// posts for the index page
const indexPosts = [];
let indexTemplate = fs.readFileSync(path.resolve(__dirname, '../', 'templates', 'index.gmi'), 'utf-8');
for (let i = 0; i < posts.length; i++) {
const post = posts[i];
if (i < 10) {
indexPosts.push(post);
}
const destinationPath = path.resolve(__dirname, '../', 'mdContent', `${post.slug}.mdx`);
const content = `# ${post.frontMatter.title}\n\n${post.frontMatter.date}, by: Jonathan M. Hethey\n\n${post.content}`;
console.log(`writing ${post.slug}.mdx`);
fs.writeFileSync(destinationPath, content, 'utf-8');
}
// instead of using a templating engine we're going to stick stuff in this string
let indexPostsString = '';
indexPosts.forEach(post => {
indexPostsString += `=> ${post.frontMatter.slug}.gmi ${post.frontMatter.title} - (${post.frontMatter.date})\n`
});
console.log('buliding index.gmi')
indexTemplate = indexTemplate.replace('[PLACEHOLDER]', indexPostsString)
const indexDestinationPath = path.resolve(__dirname, '../', 'content', `index.gmi`);
fs.writeFileSync(indexDestinationPath, indexTemplate, 'utf-8');
The most important parts are:
We're finding the directory where all the mdx posts are:
const contentPath = path.resolve(__dirname, '../', '../', 'jonathanmh.com', 'posts');
We're not just copying the file, but we're writing title and content to a new mdx file!
const content = `# ${post.frontMatter.title}\n\n${post.frontMatter.date}, by: Jonathan M. Hethey\n\n${post.content}`;
We're building a gemtext string from a template and writing the last 10 blog posts to it:
indexPosts.forEach(post => {
indexPostsString += `=> ${post.frontMatter.slug}.gmi ${post.frontMatter.title} - (${post.frontMatter.date})\n`
});
console.log('buliding index.gmi')
indexTemplate = indexTemplate.replace('[PLACEHOLDER]', indexPostsString)
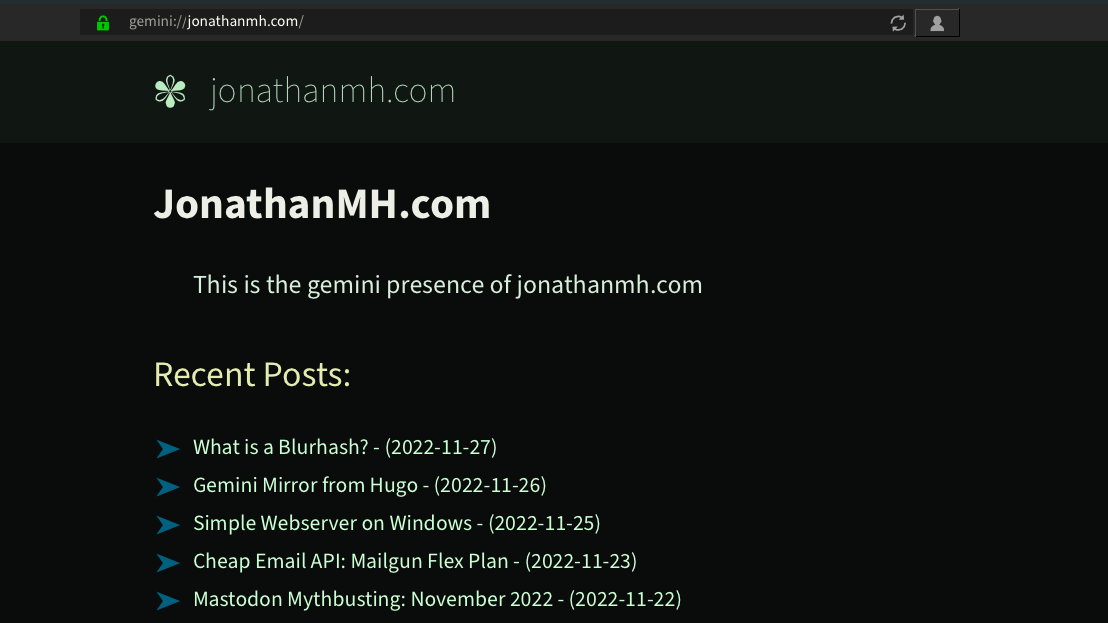
with my index.gmi template looking like this:
# JonathanMH.com
This is the gemini presence of jonathanmh.com
## Recent Posts:
[PLACEHOLDER]
=> https://jonathanmh.com For an http version of this site
=> https://streamers.social/@jonathanmh I'm on Mastodon
=> Full Archive /archive.gmi
This is pretty crude, but does what we want ¯\_(ツ)_/¯.
Now we still need to convert our markdown to actual gemtext, for which I use md2gemtext, which I've paired with the copy script in a small bash file:
#!/bin/bash
mkdir -p mdContent
node scripts/copyContent.js
for document in mdContent/*.mdx; do
echo converting $document
md2gemtext $document content/$(basename $document .mdx).gmi
done
Now we have a content directory full of our previously markdown, now gmi posts, hell yeah! Alright, now for the deployment!
Deploying Gemini or other NON HTTP to Dokku 🐳
The Dockerfile for this one was pretty simple, because all the work happens before the server starts, we're using agate to serve the files:
FROM rust:latest
RUN cargo install agate
WORKDIR /usr/src/blog
COPY content content
EXPOSE 1965
CMD ["agate", "--hostname=jonathanmh.com", "--addr=0.0.0.0:1965"]
I wanted my gemini blog to appear at gemini://jonathanmh.com and not at a subdomain which is why I added another dokku app and pointed my domain at it and only on port 1965, where as the main site takes care of ports 80 and 443. For that we also need the nginx-stream plugin, since the default plugin only handles http and https:
sudo dokku plugin:install https://github.com/josegonzalez/dokku-nginx-stream.git
sudo dokku apps:create gmi-jonathanmh-com
sudo dokku domains:add gmi-jonathanm.com jonathanmh.com
sudo dokku proxy:ports:remove 80 gmi-jonathanmh.com
sudo dokku proxy:ports-add gmi-jonathanmh.com tcp:1965:1965
If you get an error message like:
nginx: [emerg] "stream" directive is duplicate in /etc/nginx/nginx.conf:88
nginx: configuration file /etc/nginx/nginx.conf test failed
You can fix your config by opening /etc/nginx/nginx.conf and removing this duplicate block in the end:
stream {
include /etc/nginx/app-stream/*.conf;
}
This sometimes happens when two plugins try to install the same block and don't check for the presence of a block.
After that you can reload the main nginx config:
nginx -t
systemctl reload nginx
After deploying your app you should be able to see your gemlog at gemini://yourdomain.tld, YES! Also very cool that I can point one domain at different applications that respond on different ports, thank you dokku!
Persisting Gemini Certificates 🔐
What I didn't account for was that agate does generate a new certificate and that if a gemini browser previously accessed a page with a different cert, it will show an error page. To persist the certificates we need to mount a volume into our app at the correct directory, so that the certificate gets created the first time the container runs and then loads the same ones afterwards:
dokku storage:ensure-directory gmi-jonathanmh-agate-certs
dokku storage:mount gmi-jonathanmh.com /var/lib/dokku/data/storage/gmi-jonathanmh-agate-certs:/usr/src/blog/.certificates
# output
=====> gmi-jonathanmh.com storage information
Storage build mounts:
Storage deploy mounts:
-v /var/lib/dokku/data/storage/gmi-jonathanmh-agate-certs:/usr/src/blog/.certificates
Storage run mounts:
-v /var/lib/dokku/data/storage/gmi-jonathanmh-agate-certs:/usr/src/blog/.certificates
dokku ps:restart gmi-jonathanmh.com
If you want to make sure it worked, you can run dokku ps:restart gmi-jonathanmh.com and then reload the page in your gemini browser. If you get not certificate warning, it is still using the same cert, even after the container being restarted.
Summary
This was a fun one and it's really nice to see that my content migration paid off. Having an uncomplicated way to access the text part of the content available without joining over 30 tables and being able to parse the metadate with a single NPM package is absolute gold.
Improvements I still want to make is to finish converting my legacy content to markdown, because there are a few stray HTML tags here and there sticking out in the gemlog, which I need to fix.
In the meantime, get a gemini client like Lagrange and check out gemini://jonathanmh.com